Optimization Algorithms: Overview
1. The basics
1.1. Search space size in the real world
The number of possible solutions for a planning problem can be mind blowing. For example:
-
Four queens has
256possible solutions (4^4) and two optimal solutions. -
Five queens has
3125possible solutions (5^5) and one optimal solution. -
Eight queens has
16777216possible solutions (8^8) and 92 optimal solutions. -
64 queens has more than
10^115possible solutions (64^64). -
Most real-life planning problems have an incredible number of possible solutions and only one or a few optimal solutions.
For comparison: the minimal number of atoms in the known universe (10^80). As a planning problem gets bigger, the search space tends to blow up really fast. Adding only one extra planning entity or planning value can heavily multiply the running time of some algorithms. Calculating the number of possible solutions depends on the design of the domain model:
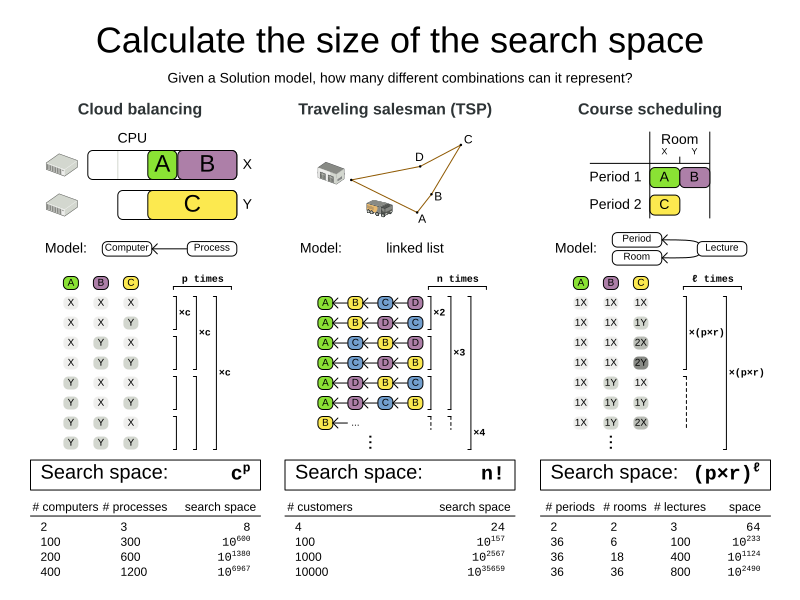
|
This search space size calculation includes infeasible solutions (if they can be represented by the model), because:
Even in cases where adding some of the hard constraints in the formula is practical, the resulting search space is still huge. |
An algorithm that checks every possible solution (even with pruning, such as in Branch And Bound) can easily run for billions of years on a single real-life planning problem. The aim is to find the best solution in the available timeframe. Planning competitions (such as the International Timetabling Competition) show that Local Search usually performs best for real-world problems given real-world time limitations.
1.2. Does Timefold Solver find the optimal solution?
The business wants the optimal solution, but they also have other requirements:
-
Scale out: Large production data sets must not crash and have also good results.
-
Optimize the right problem: The constraints must match the actual business needs.
-
Available time: The solution must be found in time, before it becomes useless to execute.
-
Reliability: Every data set must have at least a decent result (better than a human planner).
Given these requirements, and despite the promises of some salesmen, it is usually impossible for anyone or anything to find the optimal solution. Therefore, Timefold Solver focuses on finding the best solution in available time.
The nature of NP-complete problems make scaling a prime concern.
|
The quality of a result from a small data set is no indication of the quality of a result from a large data set. |
Scaling issues cannot be mitigated by hardware purchases later on. Start testing with a production sized data set as soon as possible. Do not assess quality on small data sets (unless production encounters only such data sets). Instead, solve a production sized data set and compare the results of longer executions, different algorithms and - if available - the human planner.
1.3. Supported optimization algorithms
Timefold Solver supports three families of optimization algorithms: Exhaustive Search, Construction Heuristics and Metaheuristics. In practice, Metaheuristics (in combination with Construction Heuristics to initialize) are the recommended choice:
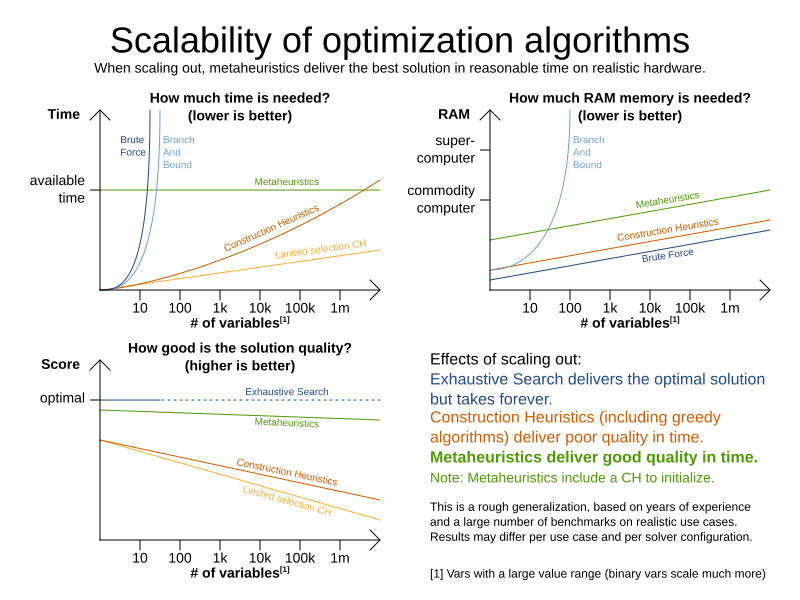
Each of these algorithm families have multiple optimization algorithms:
| Algorithm | Scalable? | Optimal? | Easy to use? | Tweakable? | Requires CH? |
|---|---|---|---|---|---|
Exhaustive Search (ES) |
|||||
0/5 |
5/5 |
5/5 |
0/5 |
No |
|
0/5 |
5/5 |
4/5 |
2/5 |
No |
|
5/5 |
1/5 |
5/5 |
1/5 |
No |
|
5/5 |
2/5 |
4/5 |
2/5 |
No |
|
5/5 |
2/5 |
4/5 |
2/5 |
No |
|
5/5 |
2/5 |
4/5 |
2/5 |
No |
|
5/5 |
2/5 |
4/5 |
2/5 |
No |
|
5/5 |
2/5 |
4/5 |
2/5 |
No |
|
3/5 |
2/5 |
5/5 |
2/5 |
No |
|
3/5 |
2/5 |
5/5 |
2/5 |
No |
|
Metaheuristics (MH) |
|||||
Local Search (LS) |
|||||
5/5 |
2/5 |
4/5 |
3/5 |
Yes |
|
5/5 |
4/5 |
3/5 |
5/5 |
Yes |
|
5/5 |
4/5 |
2/5 |
5/5 |
Yes |
|
5/5 |
4/5 |
3/5 |
5/5 |
Yes |
|
5/5 |
4/5 |
3/5 |
5/5 |
Yes |
|
5/5 |
4/5 |
3/5 |
5/5 |
Yes |
|
3/5 |
3/5 |
2/5 |
5/5 |
Yes |
|
To learn more about metaheuristics, see Essentials of Metaheuristics or Clever Algorithms.
1.4. Which optimization algorithms should I use?
The best optimization algorithm configuration to use depends heavily on your use case. However, this basic procedure provides a good starting configuration that will produce better than average results.
-
Start with a quick configuration that involves little or no configuration and optimization code: See First Fit.
-
Next, implement planning entity difficulty comparison and turn it into First Fit Decreasing.
-
Next, add Late Acceptance behind it:
-
First Fit Decreasing.
-
At this point, the return on invested time lowers and the result is likely to be sufficient.
However, this can be improved at a lower return on invested time. Use the Benchmarker and try a couple of different Tabu Search, Simulated Annealing and Late Acceptance configurations, for example:
-
First Fit Decreasing
Use the Benchmarker to improve the values for the size parameters.
Other experiments can also be run. For example, the following multiple algorithms can be combined together:
-
First Fit Decreasing
-
Late Acceptance (relatively long time)
-
Tabu Search (relatively short time)
2. Architecture
Timefold Solver combines optimization algorithms (metaheuristics, …) with score calculation by a score calculation engine. This combination is very efficient, because:
-
A score calculation engine is great for calculating the score of a solution of a planning problem. It makes it easy and scalable to add additional soft or hard constraints. It does incremental score calculation (deltas) without any extra code. However it tends to be not suitable to actually find new solutions.
-
An optimization algorithm is great at finding new improving solutions for a planning problem, without necessarily brute-forcing every possibility. However, it needs to know the score of a solution and offers no support in calculating that score efficiently.
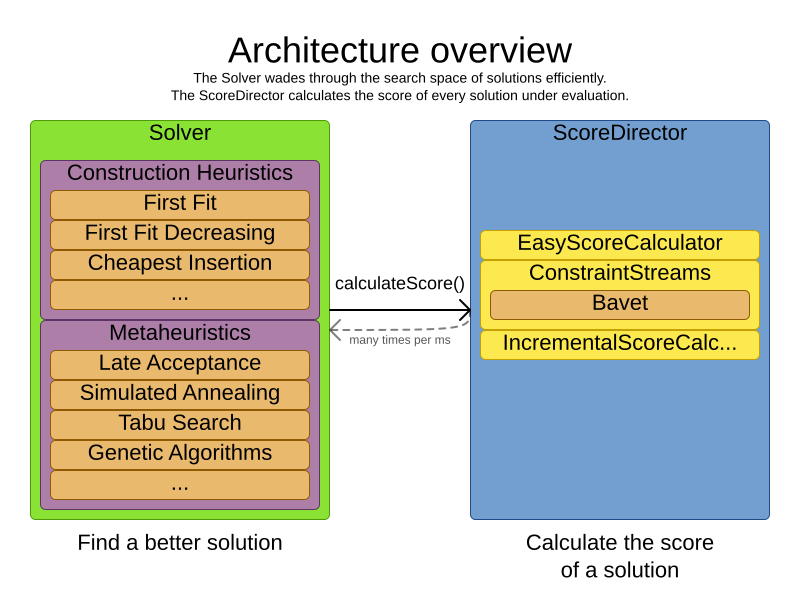
2.1. Power tweaking or default parameter values
Many optimization algorithms have parameters that affect results and scalability. Timefold Solver applies configuration by exception, so all optimization algorithms have default parameter values. This is very similar to the Garbage Collection parameters in a JVM: most users have no need to tweak them, but power users often do.
The default parameter values are sufficient for many cases (and especially for prototypes), but if development time allows, it may be beneficial to power tweak them with the benchmarker for better results and scalability on a specific use case. The documentation for each optimization algorithm also declares the advanced configuration for power tweaking.
|
The default value of parameters will change between minor versions, to improve them for most users. The advanced configuration can be used to prevent unwanted changes, however, this is not recommended. |
2.2. Solver phase
A Solver can use multiple optimization algorithms in sequence.
Each optimization algorithm is represented by one solver Phase.
There is never more than one Phase solving at the same time.
|
Some |
Here is a configuration that runs three phases in sequence:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
...
<constructionHeuristic>
... <!-- First phase: First Fit Decreasing -->
</constructionHeuristic>
<localSearch>
... <!-- Second phase: Late Acceptance -->
</localSearch>
<localSearch>
... <!-- Third phase: Tabu Search -->
</localSearch>
</solver>The solver phases are run in the order defined by solver configuration.
-
When the first
Phaseterminates, the secondPhasestarts, and so on. -
When the last
Phaseterminates, theSolverterminates.
Usually, a Solver will first run a construction heuristic and then run one or multiple metaheuristics:
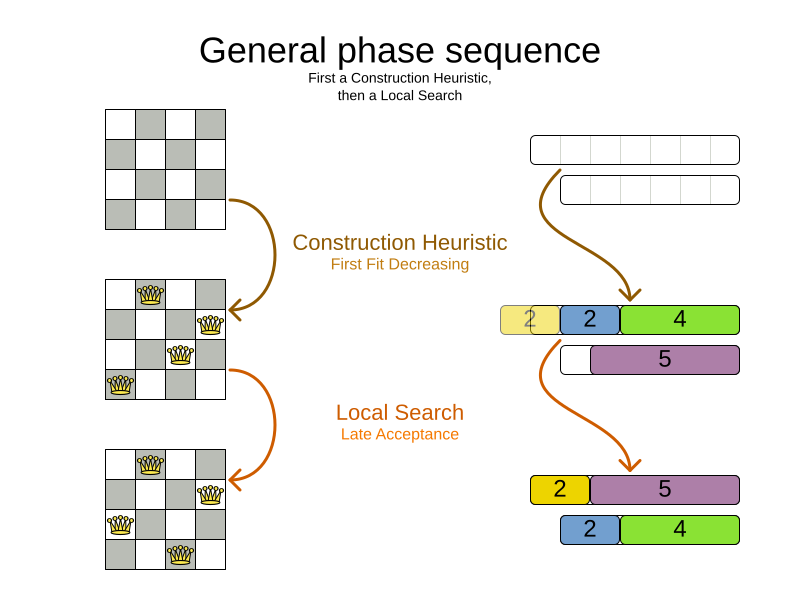
If no phases are configured, Timefold Solver will default to a Construction Heuristic phase followed by a Local Search phase.
Some phases (especially construction heuristics) will terminate automatically.
Other phases (especially metaheuristics) will only terminate if the Phase is configured to terminate:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
...
<termination><!-- Solver termination -->
<secondsSpentLimit>90</secondsSpentLimit>
</termination>
<localSearch>
<termination><!-- Phase termination -->
<secondsSpentLimit>60</secondsSpentLimit><!-- Give the next phase a chance to run too, before the Solver terminates -->
</termination>
...
</localSearch>
<localSearch>
...
</localSearch>
</solver>If the Solver terminates (before the last Phase terminates itself),
the current phase is terminated and all subsequent phases will not run.
2.3. Scope overview
A solver will iteratively run phases. Each phase will usually iteratively run steps. Each step, in turn, usually iteratively runs moves. These form four nested scopes:
-
Solver
-
Phase
-
Step
-
Move
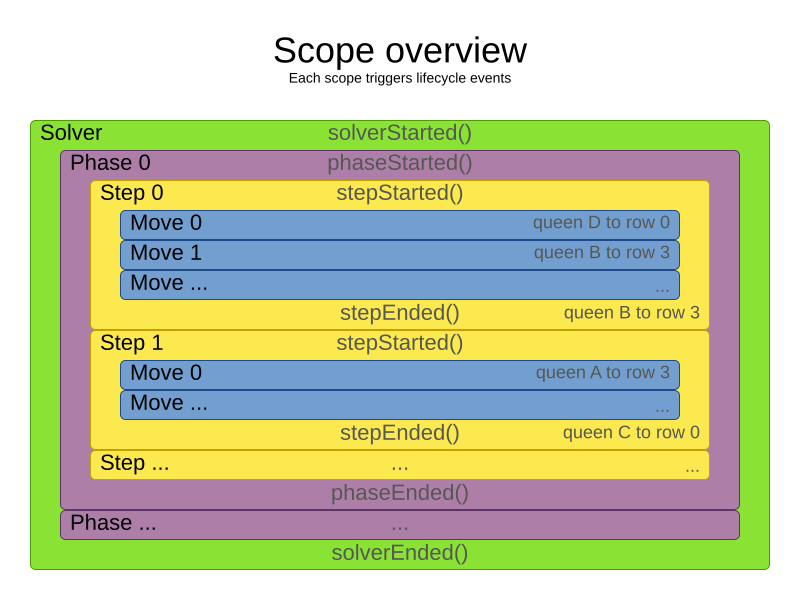
Configure logging to display the log messages of each scope.
2.4. Termination
Not all phases terminate automatically and may take a significant amount of time.
A Solver can be terminated synchronously by up-front configuration, or asynchronously from another thread.
Metaheuristic phases in particular need to be instructed to stop solving. This can be because of a number of reasons, for example, if the time is up, or the perfect score has been reached just before its solution is used. Finding the optimal solution cannot be relied on (unless you know the optimal score), because a metaheuristic algorithm is generally unaware of the optimal solution.
This is not an issue for real-life problems, as finding the optimal solution may take more time than is available. Finding the best solution in the available time is the most important outcome.
|
If no termination is configured (and a metaheuristic algorithm is used), the |
For synchronous termination, configure a Termination on a Solver or a Phase when it needs to stop.
Every Termination can calculate a time gradient (needed for some optimization algorithms),
which is a ratio between the time already spent solving and the estimated entire solving time of the Solver or Phase.
2.4.1. Time spent termination
Terminates when an amount of time has been used.
<termination>
<!-- 2 minutes and 30 seconds in ISO 8601 format P[n]Y[n]M[n]DT[n]H[n]M[n]S -->
<spentLimit>PT2M30S</spentLimit>
</termination>Alternatively to a java.util.Duration in ISO 8601 format, you can also use:
-
Milliseconds
<termination> <millisecondsSpentLimit>500</millisecondsSpentLimit> </termination> -
Seconds
<termination> <secondsSpentLimit>10</secondsSpentLimit> </termination> -
Minutes
<termination> <minutesSpentLimit>5</minutesSpentLimit> </termination> -
Hours
<termination> <hoursSpentLimit>1</hoursSpentLimit> </termination> -
Days
<termination> <daysSpentLimit>2</daysSpentLimit> </termination>
Multiple time types can be used together, for example to configure 150 minutes, either configure it directly:
<termination>
<minutesSpentLimit>150</minutesSpentLimit>
</termination>Or use a combination that sums up to 150 minutes:
<termination>
<hoursSpentLimit>2</hoursSpentLimit>
<minutesSpentLimit>30</minutesSpentLimit>
</termination>|
This
|
2.4.2. Unimproved time spent termination
Terminates when the best score has not improved in a specified amount of time. Each time a new best solution is found, the timer basically resets.
<localSearch>
<termination>
<!-- 2 minutes and 30 seconds in ISO 8601 format P[n]Y[n]M[n]DT[n]H[n]M[n]S -->
<unimprovedSpentLimit>PT2M30S</unimprovedSpentLimit>
</termination>
</localSearch>Alternatively to a java.util.Duration in ISO 8601 format, you can also use:
-
Milliseconds
<localSearch> <termination> <unimprovedMillisecondsSpentLimit>500</unimprovedMillisecondsSpentLimit> </termination> </localSearch> -
Seconds
<localSearch> <termination> <unimprovedSecondsSpentLimit>10</unimprovedSecondsSpentLimit> </termination> </localSearch> -
Minutes
<localSearch> <termination> <unimprovedMinutesSpentLimit>5</unimprovedMinutesSpentLimit> </termination> </localSearch> -
Hours
<localSearch> <termination> <unimprovedHoursSpentLimit>1</unimprovedHoursSpentLimit> </termination> </localSearch> -
Days
<localSearch> <termination> <unimprovedDaysSpentLimit>1</unimprovedDaysSpentLimit> </termination> </localSearch>
Just like time spent termination, combinations are summed up.
It is preffered to configure this termination on a specific Phase (such as <localSearch>) instead of on the Solver itself.
Several phases, such as construction heuristics, do not count towards this termination because they only trigger new best solution events when they are done. If such a phase is encountered, the termination is disabled and when the next phase is started, the termination is enabled again and the timer resets back to zero. In the most typical case, where a local search phase follows a construction heuristic phase, the termination will only trigger if the local search phase does not improve the best solution for the specified time.
|
This
|
Optionally, configure a score difference threshold by which the best score must improve in the specified time.
For example, if the score doesn’t improve by at least 100 soft points every 30 seconds or less, it terminates:
<localSearch>
<termination>
<unimprovedSecondsSpentLimit>30</unimprovedSecondsSpentLimit>
<unimprovedScoreDifferenceThreshold>0hard/100soft</unimprovedScoreDifferenceThreshold>
</termination>
</localSearch>If the score improves by 1 hard point and drops 900 soft points, it’s still meets the threshold,
because 1hard/-900soft is larger than the threshold 0hard/100soft.
On the other hand, a threshold of 1hard/0soft is not met by any new best solution
that improves 1 hard point at the expense of 1 or more soft points,
because 1hard/-100soft is smaller than the threshold 1hard/0soft.
To require a feasibility improvement every 30 seconds while avoiding the pitfall above,
use a wildcard * for lower score levels that are allowed to deteriorate if a higher score level improves:
<localSearch>
<termination>
<unimprovedSecondsSpentLimit>30</unimprovedSecondsSpentLimit>
<unimprovedScoreDifferenceThreshold>1hard/*soft</unimprovedScoreDifferenceThreshold>
</termination>
</localSearch>This effectively implies a threshold of 1hard/-2147483648soft, because it relies on Integer.MIN_VALUE.
2.4.3. BestScoreTermination
BestScoreTermination terminates when a certain score has been reached.
Use this Termination where the perfect score is known,
for example for four queens (which uses a SimpleScore):
<termination>
<bestScoreLimit>0</bestScoreLimit>
</termination>A planning problem with a HardSoftScore may look like this:
<termination>
<bestScoreLimit>0hard/-5000soft</bestScoreLimit>
</termination>A planning problem with a BendableScore with three hard levels and one soft level may look like this:
<termination>
<bestScoreLimit>[0/0/0]hard/[-5000]soft</bestScoreLimit>
</termination>In this instance, Termination once a feasible solution has been reached is not practical because it requires a bestScoreLimit such as 0hard/-2147483648soft. Use the next termination instead.
2.4.4. BestScoreFeasibleTermination
Terminates as soon as a feasible solution has been discovered.
<termination>
<bestScoreFeasible>true</bestScoreFeasible>
</termination>This Termination is usually combined with other terminations.
2.4.5. StepCountTermination
Terminates when a number of steps has been reached. This is useful for hardware performance independent runs.
<localSearch>
<termination>
<stepCountLimit>100</stepCountLimit>
</termination>
</localSearch>This Termination can only be used for a Phase (such as <localSearch>), not for the Solver itself.
2.4.6. UnimprovedStepCountTermination
Terminates when the best score has not improved in a number of steps. This is useful for hardware performance independent runs.
<localSearch>
<termination>
<unimprovedStepCountLimit>100</unimprovedStepCountLimit>
</termination>
</localSearch>If the score has not improved recently, it is unlikely to improve in a reasonable timeframe. It has been observed that once a new best solution is found (even after a long time without improvement on the best solution), the next few steps tend to improve the best solution.
This Termination can only be used for a Phase (such as <localSearch>), not for the Solver itself.
2.4.7. ScoreCalculationCountTermination
ScoreCalculationCountTermination terminates when a number of score calculations have been reached.
This is often the sum of the number of moves and the number of steps.
This is useful for benchmarking.
<termination>
<scoreCalculationCountLimit>100000</scoreCalculationCountLimit>
</termination>Switching EnvironmentMode can heavily impact when this termination ends.
2.4.8. MoveCountTermination
MoveCountTermination terminates when a number of evaluated moves have been reached.
This is useful for benchmarking.
<termination>
<moveCountLimit>100000</moveCountLimit>
</termination>Switching EnvironmentMode can heavily impact when this termination ends.
2.4.9. Combining multiple terminations
Terminations can be combined, for example: terminate after 100 steps or if a score of 0 has been reached:
<termination>
<terminationCompositionStyle>OR</terminationCompositionStyle>
<bestScoreLimit>0</bestScoreLimit>
<stepCountLimit>100</stepCountLimit>
</termination>Alternatively you can use AND, for example: terminate after reaching a feasible score of at least -100 and no improvements in 5 steps:
<termination>
<terminationCompositionStyle>AND</terminationCompositionStyle>
<bestScoreLimit>-100</bestScoreLimit>
<unimprovedStepCountLimit>5</unimprovedStepCountLimit>
</termination>This example ensures it does not just terminate after finding a feasible solution, but also completes any obvious improvements on that solution before terminating.
2.4.10. Asynchronous termination from another thread
Asynchronous termination cannot be configured by a Termination as it is impossible to predict when and if it will occur.
For example, a user action or a server restart could require a solver to terminate earlier than predicted.
To terminate a solver from another thread asynchronously
call the terminateEarly() method from another thread:
-
Java
-
Python
solver.terminateEarly();solver.terminate_early()The solver then terminates at its earliest convenience.
After termination, the Solver.solve(Solution) method returns in the solver thread (which is the original thread that called it).
|
When an To guarantee a graceful shutdown of a thread pool that contains solver threads,
an interrupt of a solver thread has the same effect as calling |
2.5. SolverEventListener
Each time a new best solution is found, a new BestSolutionChangedEvent is fired in the Solver thread.
To listen to such events, add a SolverEventListener to the Solver:
-
Java
-
Python
public interface Solver<Solution_> {
...
void addEventListener(SolverEventListener<S> eventListener);
void removeEventListener(SolverEventListener<S> eventListener);
}class Solver(Generic[Solution_]):
...
def add_event_listener(self, event_listener: Callable[[BestSolutionChangedEvent[Solution_]], None]):
...
def remove_event_listener(self, event_listener: Callable[[BestSolutionChangedEvent[Solution_]], None]):
...The BestSolutionChangedEvent's newBestSolution may not be initialized or feasible.
Use the isFeasible() method on BestSolutionChangedEvent's new best Score to detect such cases.
Use Score.isSolutionInitialized() instead of Score.isFeasible() to only ignore uninitialized solutions,
but also accept infeasible solutions.
|
The |
2.6. Custom solver phase
|
This feature is not yet supported in Timefold Solver for Python. |
Run a custom optimization algorithm between phases or before the first phase to initialize the solution, or to get a better score quickly.
You will still want to reuse the score calculation.
For example, to implement a custom Construction Heuristic without implementing an entire Phase.
|
Most of the time, a custom solver phase is not worth the development time investment.
Construction Heuristics are configurable,
|
The CustomPhaseCommand interface appears as follows:
public interface CustomPhaseCommand<Solution_> {
...
void changeWorkingSolution(ScoreDirector<Solution_> scoreDirector);
}|
Any change on the planning entities in a |
|
Do not change any of the problem facts in a |
Configure the CustomPhaseCommand in the solver configuration:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
...
<customPhase>
<customPhaseCommandClass>...MyCustomPhase</customPhaseCommandClass>
</customPhase>
... <!-- Other phases -->
</solver>Configure multiple customPhaseCommandClass instances to run them in sequence.
|
If the changes of a |
|
If the |
To configure values of a CustomPhaseCommand dynamically in the solver configuration
(so the Benchmarker can tweak those parameters),
add the customProperties element and use custom properties:
<customPhase>
<customPhaseCommandClass>...MyCustomPhase</customPhaseCommandClass>
<customProperties>
<property name="mySelectionSize" value="5"/>
</customProperties>
</customPhase>2.7. No change solver phase
In rare cases, it’s useful not to run any solver phases.
But by default, configuring no phase will trigger running the default phases.
To avoid those, configure a NoChangePhase:
<solver xmlns="https://timefold.ai/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://timefold.ai/xsd/solver https://timefold.ai/xsd/solver/solver.xsd">
...
<noChangePhase/>
</solver>3. Move and neighborhood selection
3.1. Move and neighborhood introduction
3.1.1. What is a Move?
A Move is a change (or set of changes) from a solution A to a solution B.
For example, the move below changes queen C from row 0 to row 2:
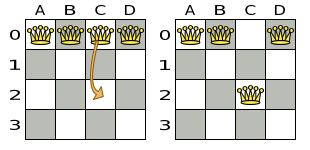
The new solution is called a neighbor of the original solution, because it can be reached in a single Move.
Although a single move can change multiple queens,
the neighbors of a solution should always be a tiny subset of all possible solutions.
For example, on that original solution, these are all possible changeMoves:
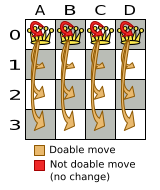
If we ignore the four changeMoves that have no impact and are therefore not doable, we can see that the number of moves is n * (n - 1) = 12.
This is far less than the number of possible solutions, which is n ^ n = 256.
As the problem scales out, the number of possible moves increases far less than the number of possible solutions.
Yet, in four changeMoves or less we can reach any solution.
For example we can reach a very different solution in three changeMoves:
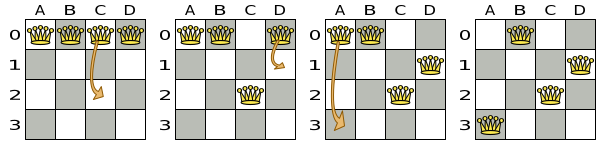
|
There are many other types of moves besides A |
All optimization algorithms use Moves to transition from one solution to a neighbor solution.
Therefore, all the optimization algorithms are confronted with Move selection: the craft of creating and iterating moves efficiently and the art of finding the most promising subset of random moves to evaluate first.
3.1.2. What is a MoveSelector?
A MoveSelector's main function is to create Iterator<Move> when needed.
An optimization algorithm will iterate through a subset of those moves.
Here’s an example how to configure a changeMoveSelector for the optimization algorithm Local Search:
<localSearch>
<changeMoveSelector/>
...
</localSearch>Out of the box, this works and all properties of the changeMoveSelector are defaulted sensibly (unless that fails fast due to ambiguity). On the other hand, the configuration can be customized significantly for specific use cases.
For example: you might want to configure a filter to discard pointless moves.
3.1.3. Subselecting of entities, values, and other moves
To create a Move, a MoveSelector needs to select one or more planning entities and/or planning values to move.
Just like MoveSelectors, EntitySelectors and ValueSelectors need to support a similar feature set (such as scalable just-in-time selection). Therefore, they all implement a common interface Selector and they are configured similarly.
A MoveSelector is often composed out of EntitySelectors, ValueSelectors or even other MoveSelectors, which can be configured individually if desired:
<unionMoveSelector>
<changeMoveSelector>
<entitySelector>
...
</entitySelector>
<valueSelector>
...
</valueSelector>
...
</changeMoveSelector>
<swapMoveSelector>
...
</swapMoveSelector>
</unionMoveSelector>Together, this structure forms a Selector tree:
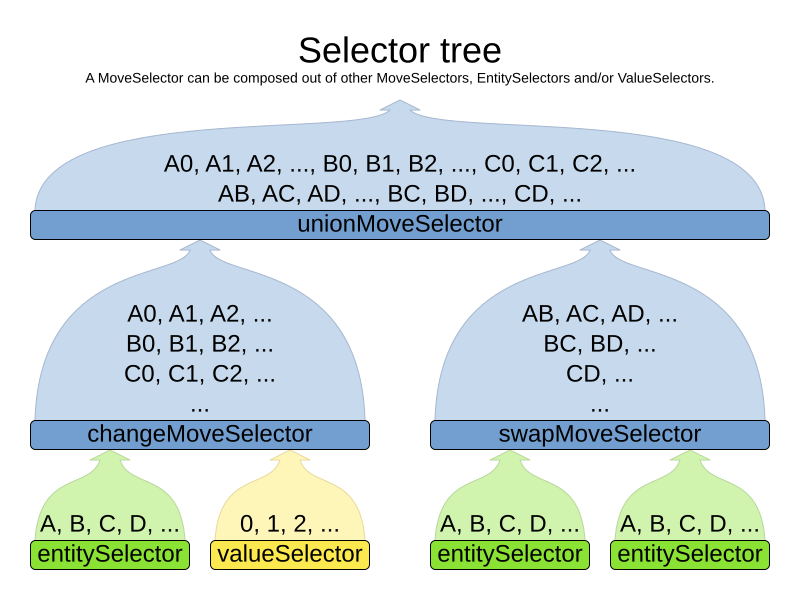
The root of this tree is a MoveSelector which is injected into the optimization algorithm implementation to be (partially) iterated in every step.
For a full list of MoveSelector implementations available out of the box,
see Move Selector reference.
3.2. Combining multiple MoveSelectors
3.2.1. unionMoveSelector
A unionMoveSelector selects a Move by selecting one of its MoveSelector children to supply the next Move.
Simplest configuration:
<unionMoveSelector>
<...MoveSelector/>
<...MoveSelector/>
<...MoveSelector/>
...
</unionMoveSelector>Advanced configuration:
<unionMoveSelector>
... <!-- Normal selector properties -->
<changeMoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</changeMoveSelector>
<swapMoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</swapMoveSelector>
<...MoveSelector>
<fixedProbabilityWeight>...</fixedProbabilityWeight>
...
</...MoveSelector>
...
<selectorProbabilityWeightFactoryClass>...ProbabilityWeightFactory</selectorProbabilityWeightFactoryClass>
</unionMoveSelector>The selectorProbabilityWeightFactory determines in selectionOrder RANDOM how often a MoveSelector child is selected to supply the next Move.
By default, each MoveSelector child has the same chance of being selected.
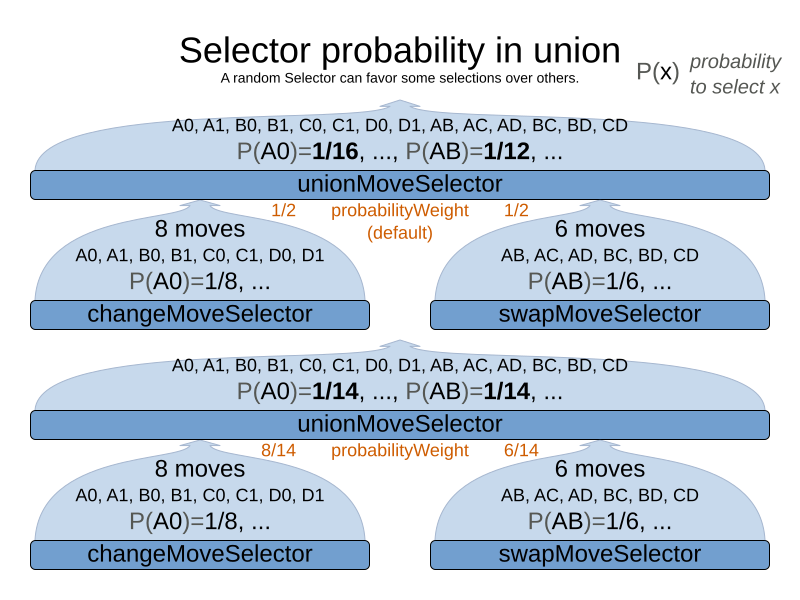
Change the fixedProbabilityWeight of such a child to select it more often.
For example, the unionMoveSelector can return a SwapMove twice as often as a ChangeMove:
<unionMoveSelector>
<changeMoveSelector>
<fixedProbabilityWeight>1.0</fixedProbabilityWeight>
...
</changeMoveSelector>
<swapMoveSelector>
<fixedProbabilityWeight>2.0</fixedProbabilityWeight>
...
</swapMoveSelector>
</unionMoveSelector>The number of possible ChangeMoves is very different from the number of possible SwapMoves and furthermore it’s problem dependent.
To give each individual Move the same selection chance (as opposed to each MoveSelector), use the FairSelectorProbabilityWeightFactory:
<unionMoveSelector>
<changeMoveSelector/>
<swapMoveSelector/>
<selectorProbabilityWeightFactoryClass>ai.timefold.solver.core.impl.heuristic.selector.common.decorator.FairSelectorProbabilityWeightFactory</selectorProbabilityWeightFactoryClass>
</unionMoveSelector>3.2.2. cartesianProductMoveSelector
A cartesianProductMoveSelector selects a new CompositeMove.
It builds that CompositeMove by selecting one Move per MoveSelector child and adding it to the CompositeMove.
Simplest configuration:
<cartesianProductMoveSelector>
<...MoveSelector/>
<...MoveSelector/>
<...MoveSelector/>
...
</cartesianProductMoveSelector>Advanced configuration:
<cartesianProductMoveSelector>
... <!-- Normal selector properties -->
<changeMoveSelector>
...
</changeMoveSelector>
<swapMoveSelector>
...
</swapMoveSelector>
<...MoveSelector>
...
</...MoveSelector>
...
<ignoreEmptyChildIterators>true</ignoreEmptyChildIterators>
</cartesianProductMoveSelector>The ignoreEmptyChildIterators property (true by default) will ignore every empty childMoveSelector to avoid returning no moves.
For example: a cartesian product of changeMoveSelector A and B, for which B is empty (because all it’s entities are pinned) returns no move if ignoreEmptyChildIterators is false and the moves of A if ignoreEmptyChildIterators is true.
To enforce that two child selectors use the same entity or value efficiently, use mimic selection, not move filtering.
3.3. EntitySelector
Simplest configuration:
<entitySelector/>Advanced configuration:
<entitySelector>
... <!-- Normal selector properties -->
<entityClass>org.acme.vehiclerouting.domain.Vehicle</entityClass>
</entitySelector>The entityClass property is only required if it cannot be deduced automatically because there are multiple entity classes.
3.4. ValueSelector
Simplest configuration:
<valueSelector/>Advanced configuration:
<valueSelector variableName="room">
... <!-- Normal selector properties -->
</valueSelector>The variableName property is only required if it cannot be deduced automatically because there are multiple variables (for the related entity class).
In exotic Construction Heuristic configurations, the entityClass from the EntitySelector sometimes needs to be downcasted, which can be done with the property downcastEntityClass:
<valueSelector variableName="period">
<downcastEntityClass>...LeadingExam</downcastEntityClass>
</valueSelector>If a selected entity cannot be downcasted, the ValueSelector is empty for that entity.
3.5. General Selector features
3.5.1. CacheType: create moves ahead of time or just in time
A Selector's cacheType determines when a selection (such as a Move, an entity, a value, …)
is created and how long it lives.
Almost every Selector supports setting a cacheType:
<changeMoveSelector>
<cacheType>PHASE</cacheType>
...
</changeMoveSelector>The following cacheTypes are supported:
-
JUST_IN_TIME(default, recommended): Not cached. Construct each selection (Move, …) just before it’s used. This scales up well in memory footprint. -
STEP: Cached. Create each selection (Move, …) at the beginning of a step and cache them in a list for the remainder of the step. This scales up badly in memory footprint. -
PHASE: Cached. Create each selection (Move, …) at the beginning of a solver phase and cache them in a list for the remainder of the phase. Some selections cannot be phase cached because the list changes every step. This scales up badly in memory footprint, but has a slight performance gain. -
SOLVER: Cached. Create each selection (Move, …) at the beginning of aSolverand cache them in a list for the remainder of theSolver. Some selections cannot be solver cached because the list changes every step. This scales up badly in memory footprint, but has a slight performance gain.
A cacheType can be set on composite selectors too:
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<changeMoveSelector/>
<swapMoveSelector/>
...
</unionMoveSelector>Nested selectors of a cached selector cannot be configured to be cached themselves, unless it’s a higher cacheType.
For example: a STEP cached unionMoveSelector can contain a PHASE cached changeMoveSelector,
but it cannot contain a STEP cached changeMoveSelector.
3.5.2. SelectionOrder: original, sorted, random, shuffled, or probabilistic
A Selector's selectionOrder determines the order in which the selections (such as Moves, entities, values, …) are iterated.
An optimization algorithm will usually only iterate through a subset of its MoveSelector's selections, starting from the start, so the selectionOrder is critical to decide which Moves are actually evaluated.
Almost every Selector supports setting a selectionOrder:
<changeMoveSelector>
...
<selectionOrder>RANDOM</selectionOrder>
...
</changeMoveSelector>The following selectionOrders are supported:
-
ORIGINAL: Select the selections (Moves, entities, values, …) in default order. Each selection will be selected only once.-
For example: A0, A1, A2, A3, …, B0, B1, B2, B3, …, C0, C1, C2, C3, …
-
-
SORTED: Select the selections (
Moves, entities, values, …) in sorted order. Each selection will be selected only once. RequirescacheType >= STEP. Mostly used on anentitySelectororvalueSelectorfor construction heuristics. See sorted selection.-
For example: A0, B0, C0, …, A2, B2, C2, …, A1, B1, C1, …
-
-
RANDOM (default): Select the selections (
Moves, entities, values, …) in non-shuffled random order. A selection might be selected multiple times. This scales up well in performance because it does not require caching.-
For example: C2, A3, B1, C2, A0, C0, …
-
-
SHUFFLED: Select the selections (
Moves, entities, values, …) in shuffled random order. Each selection will be selected only once. RequirescacheType >= STEP. This scales up badly in performance, not just because it requires caching, but also because a random number is generated for each element, even if it’s not selected (which is the grand majority when scaling up).-
For example: C2, A3, B1, A0, C0, …
-
-
PROBABILISTIC: Select the selections (
Moves, entities, values, …) in random order, based on the selection probability of each element. A selection with a higher probability has a higher chance to be selected than elements with a lower probability. A selection might be selected multiple times. RequirescacheType >= STEP. Mostly used on anentitySelectororvalueSelector. See probabilistic selection.-
For example: B1, B1, A1, B2, B1, C2, B1, B1, …
-
A selectionOrder can be set on composite selectors too.
|
When a |
3.5.3. Recommended combinations of CacheType and SelectionOrder
Just in time random selection (default)
This combination is great for big use cases (10 000 entities or more), as it scales up well in memory footprint and performance.
Other combinations are often not even viable on such sizes.
It works for smaller use cases too, so it’s a good way to start out.
It’s the default, so this explicit configuration of cacheType and selectionOrder is actually obsolete:
<unionMoveSelector>
<cacheType>JUST_IN_TIME</cacheType>
<selectionOrder>RANDOM</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>Here’s how it works.
When Iterator<Move>.next() is called, a child MoveSelector is randomly selected (1), which creates a random Move (2, 3, 4) and is then returned (5):
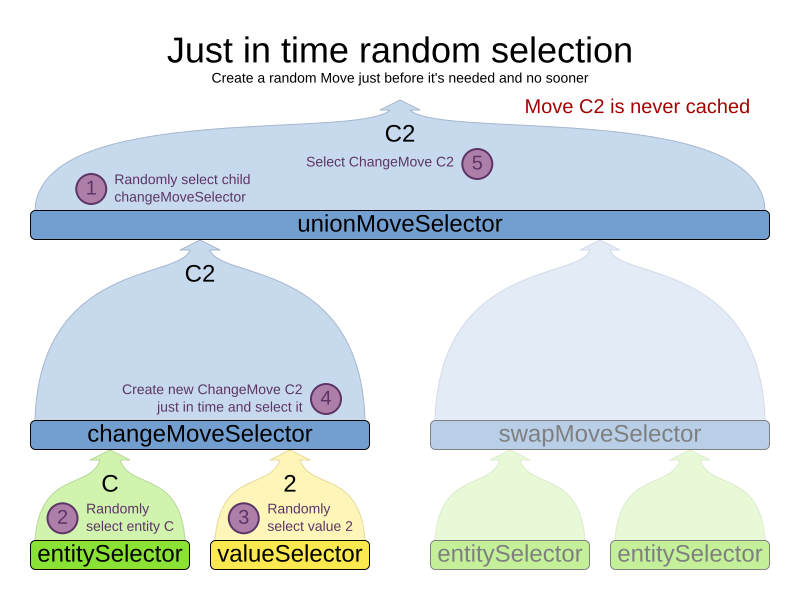
Notice that it never creates a list of Moves and it generates random numbers only for Moves that are actually selected.
Cached shuffled selection
This combination often wins for small use cases (1000 entities or less). Beyond that size, it scales up badly in memory footprint and performance.
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SHUFFLED</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>Here’s how it works: At the start of the phase (or step depending on the cacheType), all moves are created (1) and cached (2). When MoveSelector.iterator() is called, the moves are shuffled (3). When Iterator<Move>.next() is called, the next element in the shuffled list is returned (4):
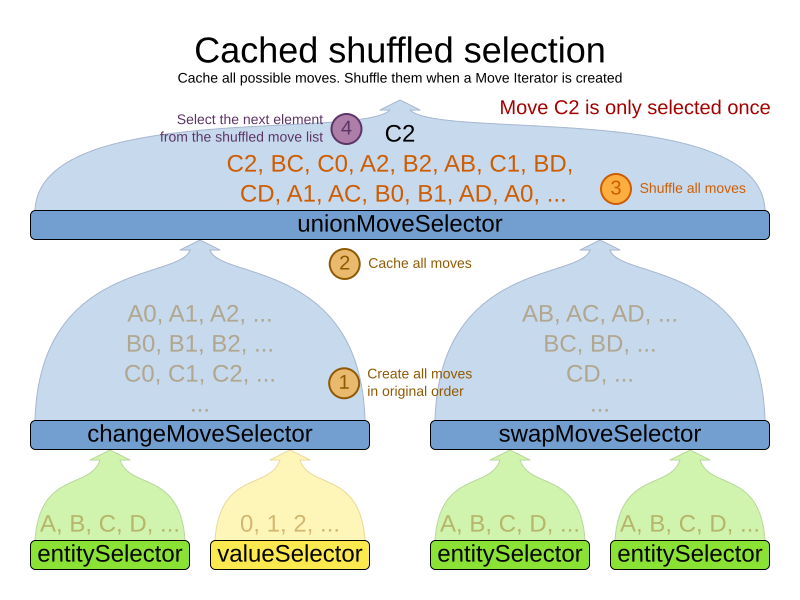
Notice that each Move will only be selected once, even though they are selected in random order.
Use cacheType PHASE if none of the (possibly nested) Selectors require STEP.
Otherwise, do something like this:
<unionMoveSelector>
<cacheType>STEP</cacheType>
<selectionOrder>SHUFFLED</selectionOrder>
<changeMoveSelector>
<cacheType>PHASE</cacheType>
</changeMoveSelector>
<swapMoveSelector>
<cacheType>PHASE</cacheType>
</swapMoveSelector>
<pillarSwapMoveSelector/><!-- Does not support cacheType PHASE -->
</unionMoveSelector>Cached random selection
This combination is often a worthy competitor for medium use cases, especially with fast stepping optimization algorithms (such as Simulated Annealing). Unlike cached shuffled selection, it doesn’t waste time shuffling the moves list at the beginning of every step.
<unionMoveSelector>
<cacheType>PHASE</cacheType>
<selectionOrder>RANDOM</selectionOrder>
<changeMoveSelector/>
<swapMoveSelector/>
</unionMoveSelector>3.5.4. Filtered selection
|
This feature is not yet supported in Timefold Solver for Python. |
There can be certain moves that you don’t want to select, because:
-
The move is pointless and would only waste CPU time. For example, swapping two lectures of the same course will result in the same score and the same schedule, because all lectures of one course are interchangeable (same teacher, same students, same topic).
-
Doing the move would break a built-in hard constraint, so the solution would be infeasible but the score function doesn’t check built-in hard constraints for performance reasons. For example, don’t change a gym lecture to a room which is not a gym room. It’s usually better to not use move filtering for such cases, because it allows the metaheuristics to temporarily break hard constraints to escape local optima.
Any built-in hard constraint must probably be filtered on every move type of every solver phase. For example if it filters the change move of Local Search, it must also filter the swap move that swaps the room of a gym lecture with another lecture for which the other lecture’s original room isn’t a gym room. Furthermore, it must also filter the change moves of the Construction Heuristics (which requires an advanced configuration).
If a move is unaccepted by the filter, it’s not executed and the score isn’t calculated.
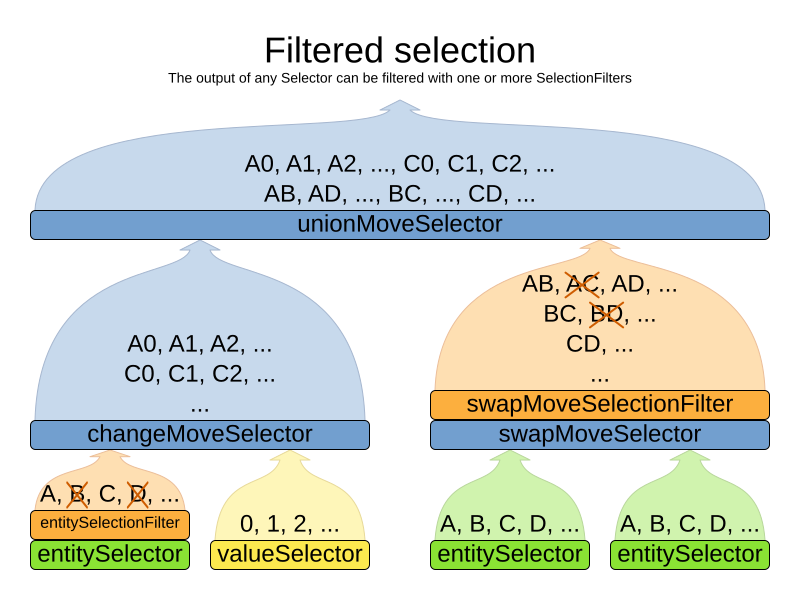
Filtering uses the interface SelectionFilter:
public interface SelectionFilter<Solution_, T> {
boolean accept(ScoreDirector<Solution_> scoreDirector, T selection);
}Implement the accept method to return false on a discarded selection (see below).
Filtered selection can happen on any Selector in the selector tree, including any MoveSelector, EntitySelector
or ValueSelector.
It works with any cacheType and selectionOrder.
|
Apply the filter on the lowest level possible. In most cases, you’ll need to know both the entity and the value involved so you’ll have to apply it on the move selector. |
|
|
Filtered move selection
Unaccepted moves will not be selected and will therefore never have their doMove() method called:
public class DifferentCourseSwapMoveFilter implements SelectionFilter<CourseSchedule, SwapMove> {
@Override
public boolean accept(ScoreDirector<CourseSchedule> scoreDirector, SwapMove move) {
Lecture leftLecture = (Lecture) move.getLeftEntity();
Lecture rightLecture = (Lecture) move.getRightEntity();
return !leftLecture.getCourse().equals(rightLecture.getCourse());
}
}Configure the filterClass on every targeted moveSelector
(potentially both in the Local Search and the Construction Heuristics if it filters ChangeMoves):
<swapMoveSelector>
<filterClass>...DifferentCourseSwapMoveFilter</filterClass>
</swapMoveSelector>Filtered entity selection
Unaccepted entities will not be selected and will therefore never be used to create a move.
public class LongLectureSelectionFilter implements SelectionFilter<CourseSchedule, Lecture> {
@Override
public boolean accept(ScoreDirector<CourseSchedule> scoreDirector, Lecture lecture) {
return lecture.isLong();
}
}Configure the filterClass on every targeted entitySelector (potentially both in the Local Search and the Construction Heuristics):
<changeMoveSelector>
<entitySelector>
<filterClass>...LongLectureSelectionFilter</filterClass>
</entitySelector>
</changeMoveSelector>If that filter should apply on all entities, configure it as a global pinningFilter instead.
Filtered value selection
Unaccepted values will not be selected and will therefore never be used to create a move.
public class LongPeriodSelectionFilter implements SelectionFilter<CourseSchedule, Period> {
@Override
public boolean accept(ScoreDirector<CourseSchedule> scoreDirector, Period period) {
return period();
}
}Configure the filterClass on every targeted valueSelector (potentially both in the Local Search and the Construction Heuristics):
<changeMoveSelector>
<valueSelector>
<filterClass>...LongPeriodSelectionFilter</filterClass>
</valueSelector>
</changeMoveSelector>3.5.5. Sorted selection
Sorted selection can happen on any Selector in the selector tree, including any MoveSelector, EntitySelector or ValueSelector.
It does not work with cacheType JUST_IN_TIME and it only works with selectionOrder SORTED.
It’s mostly used in construction heuristics.
|
If the chosen construction heuristic implies sorting, for example |
Sorted selection by SorterManner
Some Selector types implement a SorterManner out of the box:
-
EntitySelectorsupports:-
DECREASING_DIFFICULTY: Sorts the planning entities according to decreasing planning entity difficulty. Requires that planning entity difficulty is annotated on the domain model.<entitySelector> <cacheType>PHASE</cacheType> <selectionOrder>SORTED</selectionOrder> <sorterManner>DECREASING_DIFFICULTY</sorterManner> </entitySelector>
-
-
ValueSelectorsupports:-
INCREASING_STRENGTH: Sorts the planning values according to increasing planning value strength. Requires that planning value strength is annotated on the domain model.<valueSelector> <cacheType>PHASE</cacheType> <selectionOrder>SORTED</selectionOrder> <sorterManner>INCREASING_STRENGTH</sorterManner> </valueSelector>
-
Sorted selection by Comparator
An easy way to sort a Selector is with a plain old Comparator:
public class VisitDifficultyComparator implements Comparator<Visit> {
public int compare(Visit a, Visit b) {
return new CompareToBuilder()
.append(a.getServiceDuration(), b.getServiceDuration())
.append(a.getId(), b.getId())
.toComparison();
}
}You’ll also need to configure it (unless it’s annotated on the domain model and automatically applied by the optimization algorithm):
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterComparatorClass>...VisitDifficultyComparator</sorterComparatorClass>
<sorterOrder>DESCENDING</sorterOrder>
</entitySelector>|
|
Sorted selection by SelectionSorterWeightFactory
If you need the entire solution to sort a Selector, use a SelectionSorterWeightFactory instead:
public interface SelectionSorterWeightFactory<Solution_, T> {
Comparable createSorterWeight(Solution_ solution, T selection);
}You’ll also need to configure it (unless it’s annotated on the domain model and automatically applied by the optimization algorithm):
<entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterWeightFactoryClass>...MyDifficultyWeightFactory</sorterWeightFactoryClass>
<sorterOrder>DESCENDING</sorterOrder>
</entitySelector>|
|
Sorted selection by SelectionSorter
Alternatively, you can also use the interface SelectionSorter directly:
public interface SelectionSorter<Solution_, T> {
void sort(ScoreDirector<Solution_> scoreDirector, List<T> selectionList);
} <entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>SORTED</selectionOrder>
<sorterClass>...MyEntitySorter</sorterClass>
</entitySelector>|
|
3.5.6. Probabilistic selection
|
This feature is not yet supported in Timefold Solver for Python. |
Probabilistic selection can happen on any Selector in the selector tree, including any MoveSelector, EntitySelector or ValueSelector.
It does not work with cacheType JUST_IN_TIME and it only works with selectionOrder PROBABILISTIC.
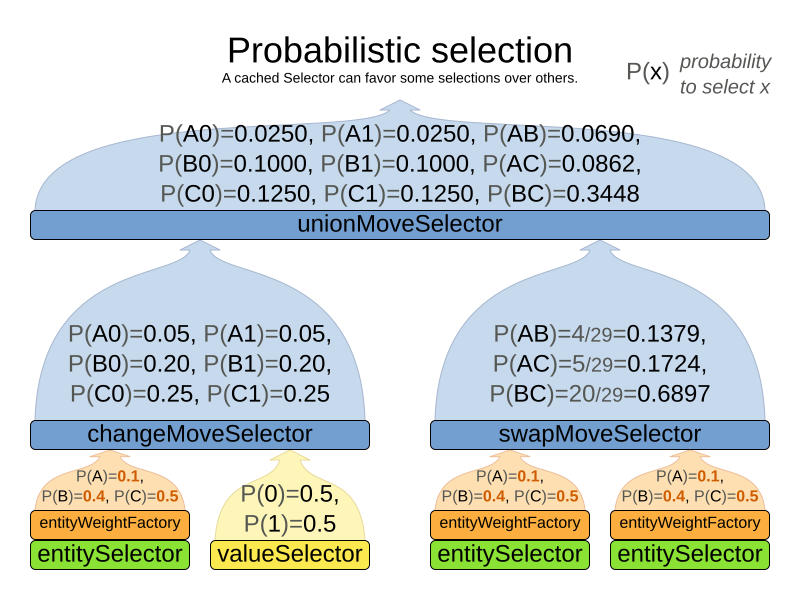
Each selection has a probabilityWeight, which determines the chance that selection will be selected:
public interface SelectionProbabilityWeightFactory<Solution_, T> {
double createProbabilityWeight(ScoreDirector<Solution_> scoreDirector, T selection);
} <entitySelector>
<cacheType>PHASE</cacheType>
<selectionOrder>PROBABILISTIC</selectionOrder>
<probabilityWeightFactoryClass>...MyEntityProbabilityWeightFactoryClass</probabilityWeightFactoryClass>
</entitySelector>Assume the following entities: lesson A (probabilityWeight 2.0), lesson B (probabilityWeight 0.5) and lesson C (probabilityWeight 0.5). Then lesson A will be selected four times more than B and C.
|
|
3.5.7. Limited selection
Selecting all possible moves sometimes does not scale well enough,
especially for construction heuristics,
which don’t support acceptedCountLimit.
To limit the number of selected selection per step, apply a selectedCountLimit on the selector:
<changeMoveSelector>
<selectedCountLimit>100</selectedCountLimit>
</changeMoveSelector>|
To scale Local Search,
setting |
3.5.8. Mimic selection (record/replay)
During mimic selection, one normal selector records its selection and one or multiple other special selectors replay that selection. The recording selector acts as a normal selector and supports all other configuration properties. A replaying selector mimics the recording selection and supports no other configuration properties.
The recording selector needs an id.
A replaying selector must reference a recorder’s id with a mimicSelectorRef:
<cartesianProductMoveSelector>
<changeMoveSelector>
<entitySelector id="entitySelector"/>
<valueSelector variableName="period"/>
</changeMoveSelector>
<changeMoveSelector>
<entitySelector mimicSelectorRef="entitySelector"/>
<valueSelector variableName="room"/>
</changeMoveSelector>
</cartesianProductMoveSelector>Mimic selection is useful to create a composite move from two moves that affect the same entity.
3.5.9. Nearby selection
|
Nearby selection is a commercial feature of Timefold Solver Enterprise Edition. It is not open source, and it is free for development use only. Learn more about Timefold. |
Read about nearby selection in the Nearby selection section of the Enterprise Edition manual.
3.6. Custom moves
|
This feature is not yet supported in Timefold Solver for Python. |
3.6.1. Which move types might be missing in my implementation?
To determine which move types might be missing in your implementation, run a Benchmarker for a short amount of time and configure it to write the best solutions to disk. Take a look at such a best solution: it will likely be a local optima. Try to figure out if there’s a move that could get out of that local optima faster.
If you find one, implement that coarse-grained move, mix it with the existing moves and benchmark it against the previous configurations to see if you want to keep it.
3.6.2. Custom moves introduction
Instead of using the generic Moves (such as ChangeMove) you can also implement your own Move.
Generic and custom MoveSelectors can be combined as desired.
A custom Move can be tailored to work to the advantage of your constraints.
For example, in examination scheduling, changing the period of an exam A
would also change the period of all the other exams that need to coincide with exam A.
A custom Move is far more work to implement and much harder to avoid bugs than a generic Move.
After implementing a custom Move, turn on environmentMode TRACED_FULL_ASSERT to check for score corruptions.
3.6.3. The Move interface
All moves implement the Move interface:
public interface Move<Solution_> {
boolean isMoveDoable(ScoreDirector<Solution_> scoreDirector);
Move<Solution_> doMove(ScoreDirector<Solution_> scoreDirector);
...
}To implement a custom move, it’s recommended to extend AbstractMove instead implementing Move directly.
Timefold Solver calls AbstractMove.doMove(ScoreDirector), which calls doMoveOnGenuineVariables(ScoreDirector).
For example, in school timetabling, this move changes one lesson to another timeslot:
public class TimeslotChangeMove extends AbstractMove<Timetable> {
private Lesson lesson;
private Timeslot toTimeslot;
public CloudComputerChangeMove(Lesson lesson, Timeslot toTimeslot) {
this.lesson = lesson;
this.toTimeslot = toTimeslot;
}
@Override
protected void doMoveOnGenuineVariables(ScoreDirector<Timetable> scoreDirector) {
scoreDirector.beforeVariableChanged(lesson, "timeslot");
lesson.setTimeslot(toTimeslot);
scoreDirector.afterVariableChanged(lesson, "timeslot");
}
// ...
}The implementation must notify the ScoreDirector of any changes it makes to planning entity’s variables:
Call the scoreDirector.beforeVariableChanged(Object, String) and scoreDirector.afterVariableChanged(Object, String)
methods directly before and after modifying an entity’s planning variable.
The example move above is a fine-grained move because it changes only one planning variable. On the other hand, a coarse-grained move changes multiple entities or multiple planning variables in a single move, usually to avoid breaking hard constraints by making multiple related changes at once. For example, a swap move is really just two change moves, but it keeps those two changes together.
|
A |
Timefold Solver automatically filters out non doable moves by calling the isMoveDoable(ScoreDirector) method on each selected move.
A non doable move is:
-
A move that changes nothing on the current solution. For example, moving lesson
L1from timeslotXto timeslotXis not doable, because it is already there. -
A move that is impossible to do on the current solution. For example, moving lesson
L1to timeslotQ(whenQisn’t in the list of lessons) is not doable because it would assign a planning value that’s not inside the planning variable’s value range.
In the school timetabling example, a move which assigns a lesson to the timeslot it’s already assigned to is not doable:
@Override
public boolean isMoveDoable(ScoreDirector<Timetable> scoreDirector) {
return !Objects.equals(lesson.getTimeslot(), toTimeslot);
}We don’t need to check if toTimeslot is in the value range,
because we only generate moves for which that is the case.
A move that is currently not doable can become doable when the working solution changes in a later step,
otherwise we probably shouldn’t have created it in the first place.
Each move has an undo move: a move which does the exact opposite. The users do not need to implement this move, as the solver is smart enough to know what to undo based on the move that was done.
A solver phase might do and undo the same Move more than once.
In fact, many solver phases will iteratively do and undo a number of moves to evaluate them,
before selecting one of those and doing that move again (without undoing it the last time).
Always implement the toString() method to keep Timefold Solver’s logs readable.
Keep it non-verbose and make it consistent
with the generic moves:
public String toString() {
return lesson + " {" + lesson.getTimeslot() + " -> " + toTimeslot + "}";
}Optionally, implement the getSimpleMoveTypeDescription() method to support
picked move statistics:
@Override
public String getSimpleMoveTypeDescription() {
return "TimeslotChangeMove(Lesson.timeslot)";
}Custom move: rebase()
For multi-threaded incremental solving,
the custom move must implement the rebase() method:
@Override
public TimeslotChangeMove rebase(ScoreDirector<Timetable> destinationScoreDirector) {
return new TimeslotChangeMove(destinationScoreDirector.lookUpWorkingObject(lesson),
destinationScoreDirector.lookUpWorkingObject(toTimeslot));
}Rebasing a move takes a move generated from one working solution and creates a new move that does the same change as the original move, but rewired as if it was generated from the destination working solution. This allows multi-threaded solving to migrate moves from one thread to another.
The lookUpWorkingObject() method translates a planning entity instance or problem fact instance
from one working solution to that of the destination’s working solution.
Internally it often uses a mapping technique based on the planning ID.
To rebase lists or arrays in bulk, use rebaseList() and rebaseArray() on AbstractMove.
Custom move: getPlanningEntities() and getPlanningValues()
A custom move should also implement the getPlanningEntities() and getPlanningValues() methods.
Those are used by entity tabu and value tabu respectively.
They are called after the Move has already been done.
@Override
public Collection<? extends Object> getPlanningEntities() {
return Collections.singletonList(lesson);
}
@Override
public Collection<? extends Object> getPlanningValues() {
return Collections.singletonList(toTimeslot);
}If the Move changes multiple planning entities, such as in a swap move,
return all of them in getPlanningEntities()
and return all their values (to which they are changing) in getPlanningValues().
@Override
public Collection<? extends Object> getPlanningEntities() {
return Arrays.asList(leftLesson, rightLesson);
}
@Override
public Collection<? extends Object> getPlanningValues() {
return Arrays.asList(leftLesson.getTimeslot(), rightLesson.getTimeslot());
}Custom move: equals() and hashCode()
A Move must implement the equals() and hashCode() methods
for move tabu.
Two moves which make the same change on a solution, should be equal ideally.
@Override
public boolean equals(Object o) {
return o instanceof TimeslotChangeMove other
&& lesson.equals(other.lesson)
&& toTimeslot.equals(other.toTimeslot);
}
@Override
public int hashCode() {
return new HashCodeBuilder()
.append(lesson)
.append(toTimeslot)
.toHashCode();
}Notice that it checks if the other move is an instance of the same move type.
This instanceof check is important because a move are compared to a move of another move type.
For example a ChangeMove and SwapMove are compared.
3.6.4. Generating custom moves
Now, let’s generate instances of this custom Move class.
There are 2 ways:
MoveListFactory: the easy way to generate custom moves
The easiest way to generate custom moves is by implementing the interface MoveListFactory:
public interface MoveListFactory<Solution_> {
List<Move> createMoveList(Solution_ solution);
}Simple configuration (which can be nested in a unionMoveSelector just like any other MoveSelector):
<moveListFactory>
<moveListFactoryClass>...MyMoveFactory</moveListFactoryClass>
</moveListFactory>Advanced configuration:
<moveListFactory>
... <!-- Normal moveSelector properties -->
<moveListFactoryClass>...MyMoveFactory</moveListFactoryClass>
<moveListFactoryCustomProperties>
...<!-- Custom properties -->
</moveListFactoryCustomProperties>
</moveListFactory>Because the MoveListFactory generates all moves at once in a List<Move>,
it does not support cacheType JUST_IN_TIME.
Therefore, moveListFactory uses cacheType STEP by default and it scales badly.
To configure values of a MoveListFactory dynamically in the solver configuration
(so the Benchmarker can tweak those parameters),
add the moveListFactoryCustomProperties element and use custom properties.
|
A custom |
MoveIteratorFactory: generate Custom moves just in time
Use this advanced form to generate custom moves Just In Time
by implementing the MoveIteratorFactory interface:
public interface MoveIteratorFactory<Solution_> {
long getSize(ScoreDirector<Solution_> scoreDirector);
Iterator<Move> createOriginalMoveIterator(ScoreDirector<Solution_> scoreDirector);
Iterator<Move> createRandomMoveIterator(ScoreDirector<Solution_> scoreDirector, Random workingRandom);
}The getSize() method must return an estimation of the size.
It doesn’t need to be correct, but it’s better too big than too small.
The createOriginalMoveIterator method is called if the selectionOrder is ORIGINAL or if it is cached.
The createRandomMoveIterator method is called for selectionOrder RANDOM combined with cacheType JUST_IN_TIME.
|
Don’t create a collection (array, list, set or map) of |
For example:
public class PossibleAssignmentsOnlyMoveIteratorFactory implements MoveIteratorFactory<MyPlanningSolution, MyChangeMove> {
@Override
public long getSize(ScoreDirector<MyPlanningSolution> scoreDirector) {
// In this case, we return the exact size, but an estimate can be used
// if it too expensive to calculate or unknown
long totalSize = 0L;
var solution = scoreDirector.getWorkingSolution();
for (MyEntity entity : solution.getEntities()) {
for (MyPlanningValue value : solution.getValues()) {
if (entity.canBeAssigned(value)) {
totalSize++;
}
}
}
return totalSize;
}
@Override
public Iterator<MyChangeMove> createOriginalMoveIterator(ScoreDirector<MyPlanningSolution> scoreDirector) {
// Only needed if selectionOrder is ORIGINAL or if it is cached
var solution = scoreDirector.getWorkingSolution();
var entities = solution.getEntities();
var values = solution.getValues();
// Assumes each entity has at least one assignable value
var firstEntityIndex = 0;
var firstValueIndex = 0;
while (!entities.get(firstEntityIndex).canBeAssigned(values.get(firstValueIndex))) {
firstValueIndex++;
}
return new Iterator<>() {
int nextEntityIndex = firstEntityIndex;
int nextValueIndex = firstValueIndex;
@Override
public boolean hasNext() {
return nextEntityIndex < entities.size();
}
@Override
public MyChangeMove next() {
var selectedEntity = entities.get(nextEntityIndex);
var selectedValue = values.get(nextValueIndex);
nextValueIndex++;
while (nextValueIndex < values.size() && !selectedEntity.canBeAssigned(values.get(nextValueIndex))) {
nextValueIndex++;
}
if (nextValueIndex >= values.size()) {
// value list exhausted, go to next entity
nextEntityIndex++;
if (nextEntityIndex < entities.size()) {
nextValueIndex = 0;
while (nextValueIndex < values.size() && !entities.get(nextEntityIndex).canBeAssigned(values.get(nextValueIndex))) {
// Assumes each entity has at least one assignable value
nextValueIndex++;
}
}
}
return new MyChangeMove(selectedEntity, selectedValue);
}
};
}
@Override
public Iterator<MyChangeMove> createRandomMoveIterator(ScoreDirector<MyPlanningSolution> scoreDirector,
Random workingRandom) {
// Not needed if selectionOrder is ORIGINAL or if it is cached
var solution = scoreDirector.getWorkingSolution();
var entities = solution.getEntities();
var values = solution.getValues();
return new Iterator<>() {
@Override
public boolean hasNext() {
return !entities.isEmpty();
}
@Override
public MyChangeMove next() {
var selectedEntity = entities.get(workingRandom.nextInt(entities.size()));
var selectedValue = values.get(workingRandom.nextInt(values.size()));
while (!selectedEntity.canBeAssigned(selectedValue)) {
// This assumes there at least one value that can be assigned to the selected entity
selectedValue = values.get(workingRandom.nextInt(values.size()));
}
return new MyChangeMove(selectedEntity, selectedValue);
}
};
}
}|
The same effect can also be accomplished using filtered selection. |
Simple configuration (which can be nested in a unionMoveSelector just like any other MoveSelector):
<moveIteratorFactory>
<moveIteratorFactoryClass>...</moveIteratorFactoryClass>
</moveIteratorFactory>Advanced configuration:
<moveIteratorFactory>
... <!-- Normal moveSelector properties -->
<moveIteratorFactoryClass>...</moveIteratorFactoryClass>
<moveIteratorFactoryCustomProperties>
...<!-- Custom properties -->
</moveIteratorFactoryCustomProperties>
</moveIteratorFactory>To configure values of a MoveIteratorFactory dynamically in the solver configuration
(so the Benchmarker can tweak those parameters),
add the moveIteratorFactoryCustomProperties element and use custom properties.
|
A custom |